
NFSv3 vs NFSv4 Storage on Proxmox: The Latency Clash That Reveals More Than You Think
When it comes to virtualization, many people still think that NFS isn’t suitable for serious workloads in their enterprise environment and that you need to rely on protocols like iSCSI or Fibre Channel to get proper performance. That mindset might have made sense years ago, but times have changed. Today, we have access to incredibly fast networks and not only in enterprise but even at home. It’s not uncommon to see 10 Gbit networking in home labs, and enterprises are already moving to 25, 40, 100, or even 400 Gbit infrastructure. So the bottleneck is no longer bandwidth rather than the protocol overhead and hardware interaction that really matters.
NFS, despite being around for decades, is often underestimated. Many still think of it as a basic file-sharing protocol, not realizing how far it’s come and how capable it is when properly configured and used with the latest versions. Especially in virtualized environments like Proxmox, NFS can be a powerful and flexible storage backend that scales very well if set up correctly. The problem is, people often judge NFS based on outdated assumptions or suboptimal configurations where they’re usually using older versions like NFSv3 without taking advantage of what newer versions offer.
In this post, we’re focusing on the differences between NFSv3 and NFSv4, especially when it comes to latency. While high throughput can be achieved by running multiple VMs in parallel or doing sequential reads, latency is a whole different challenge. And latency is becoming more and more important. Whether you’re running databases, machine learning workloads, or any latency-sensitive applications, it’s not anymore just about how fast you can push and pull data in bulk – it’s about how quickly the system responds.
That’s where NFSv4 really shines. Compared to NFSv3, it brings major improvements not just in functionality but also in how efficiently it handles operations. Features like n-connect, which allows multiple TCP connections per mount, and pNFS (Parallel NFS), which enables direct data access from clients to storage nodes, provide serious performance gains. On top of that, NFSv4 has better locking mechanisms, improved security, stateful protocol design, and more efficient metadata handling, all of which reduce round-trip times and overall latency. One major issue in such setups often relies in the default behavior, where many ones simply use NFSv3 and start complaining about the performance which is indeed often not that good. Therefore, you should take the time to properly configure NFSv4 in your environment.
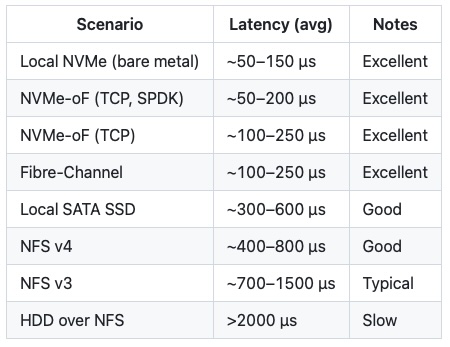
Latencies by Storage-Type
Before we’re starting with our tests on NFSv3 and NFSv4, we should have a rough idea what kind of latencies we should expect during our tests.
Latency Tests NFSv3 vs NFSv4
Within this post, we showcase the performance differences between NFSv3 and NFSv4 to prove that using NFSv4 makes a difference in virtualization setups – espeically when it comes to latency critical applications.
Test Setup
The fio tests are performed inside of a minimal Debian VM with 4 vCPU, 4GB memory, VirtIO SCSI Single. The VM is operated within a Proxmox node that is connected to a storage server by 2x 2.5Gbit networking.
Proxmox Server Node
System: Ace Magician AM06 Pro
OS: Proxmox 8.4.1
CPU: AMD Ryzen 5 5500U
Memory: 2x 32GB DDR4 3200 (Crucial RAM CT2K32G)
Network: 2x Intel I226-V (rev 04) 2.5 Gbit
Storage Server
System: GMKtec G9 NAS
OS: FreeBSD 14.3
CPU: Intel N150
Memory: 1x 12GB DDR5 4800
Disks: 2x WD Black SN7100 (NVMe, ZFS Mirror)
Network: 2x Intel I226-V (rev 04) 2.5 Gbit
NFSv3 rand-read
fio --rw=randread --name=IOPS-read --bs=4k --direct=1 --filename=/dev/sda --numjobs=1 --ioengine=libaio --iodepth=1 --refill_buffers --group_reporting --runtime=60 --time_based
IOPS-read: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=1
fio-3.33
Starting 1 process
Jobs: 1 (f=1): [r(1)][100.0%][r=5824KiB/s][r=1456 IOPS][eta 00m:00s]
IOPS-read: (groupid=0, jobs=1): err= 0: pid=552: Fri Jul 4 02:17:29 2025
read: IOPS=1641, BW=6566KiB/s (6723kB/s)(385MiB/60001msec)
slat (nsec): min=4749, max=73062, avg=9528.24, stdev=4329.94
clat (usec): min=16, max=4319, avg=597.54, stdev=142.23
lat (usec): min=39, max=4361, avg=607.07, stdev=142.69
clat percentiles (usec):
| 1.00th=[ 56], 5.00th=[ 392], 10.00th=[ 408], 20.00th=[ 424],
| 30.00th=[ 578], 40.00th=[ 627], 50.00th=[ 644], 60.00th=[ 660],
| 70.00th=[ 685], 80.00th=[ 701], 90.00th=[ 734], 95.00th=[ 758],
| 99.00th=[ 799], 99.50th=[ 824], 99.90th=[ 1004], 99.95th=[ 1467],
| 99.99th=[ 1942]
bw ( KiB/s): min= 5600, max= 7376, per=100.00%, avg=6576.94, stdev=280.60, samples=119
iops : min= 1400, max= 1844, avg=1644.24, stdev=70.15, samples=119
lat (usec) : 20=0.01%, 50=0.72%, 100=0.69%, 250=0.03%, 500=25.75%
lat (usec) : 750=67.08%, 1000=5.64%
lat (msec) : 2=0.10%, 4=0.01%, 10=0.01%
cpu : usr=1.14%, sys=2.85%, ctx=98497, majf=0, minf=11
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=98489,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
READ: bw=6566KiB/s (6723kB/s), 6566KiB/s-6566KiB/s (6723kB/s-6723kB/s), io=385MiB (403MB), run=60001-60001msec
Disk stats (read/write):
sda: ios=98336/31, merge=0/10, ticks=58412/57, in_queue=58470, util=96.42%NFSv4 rand-read
fio --rw=randread --name=IOPS-read --bs=4k --direct=1 --filename=/dev/sda --numjobs=1 --ioengine=libaio --iodepth=1 --refill_buffers --group_reporting --runtime=60 --time_based
IOPS-read: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=1
fio-3.33
Starting 1 process
Jobs: 1 (f=1): [r(1)][100.0%][r=9388KiB/s][r=2347 IOPS][eta 00m:00s]
IOPS-read: (groupid=0, jobs=1): err= 0: pid=570: Fri Jul 4 02:04:10 2025
read: IOPS=2377, BW=9509KiB/s (9737kB/s)(557MiB/60001msec)
slat (usec): min=4, max=768, avg= 7.44, stdev= 3.98
clat (usec): min=2, max=3057, avg=411.62, stdev=94.69
lat (usec): min=38, max=3090, avg=419.05, stdev=94.99
clat percentiles (usec):
| 1.00th=[ 51], 5.00th=[ 330], 10.00th=[ 338], 20.00th=[ 347],
| 30.00th=[ 363], 40.00th=[ 371], 50.00th=[ 379], 60.00th=[ 383],
| 70.00th=[ 486], 80.00th=[ 529], 90.00th=[ 545], 95.00th=[ 545],
| 99.00th=[ 570], 99.50th=[ 586], 99.90th=[ 676], 99.95th=[ 816],
| 99.99th=[ 1680]
bw ( KiB/s): min= 7712, max= 9856, per=100.00%, avg=9517.98, stdev=214.90, samples=119
iops : min= 1928, max= 2464, avg=2379.50, stdev=53.72, samples=119
lat (usec) : 4=0.01%, 20=0.01%, 50=0.94%, 100=0.47%, 250=0.01%
lat (usec) : 500=70.04%, 750=28.47%, 1000=0.03%
lat (msec) : 2=0.03%, 4=0.01%
cpu : usr=1.18%, sys=3.37%, ctx=142654, majf=0, minf=11
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=142632,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
READ: bw=9509KiB/s (9737kB/s), 9509KiB/s-9509KiB/s (9737kB/s-9737kB/s), io=557MiB (584MB), run=60001-60001msec
Disk stats (read/write):
sda: ios=142384/3, merge=0/1, ticks=58212/5, in_queue=58218, util=95.84%Latency Comparison
| Metric | NFSv3 | NFSv4.2 | Comments |
| IOPS (avg) | 1641 | 2377 | NFSv4.2 delivers ~45% higher IOPS |
| Bandwidth (avg) | 6566 KiB/s (~6.4 MiB/s) | 9509 KiB/s (~9.3 MiB/s) | NFSv4.2 has about 45% higher throughput |
| Submit Latency (slat avg) | 9528 ns (~9.5 µs) | 7.44 µs | NFSv4.2 slat significantly lower (faster) |
| Completion Latency (clat avg) | 597.54 µs | 411.62 µs | NFSv4.2 clat is ~31% lower (better latency) |
| Total Latency (lat avg) | 607.07 µs | 419.05 µs | Overall latency is ~31% better with NFSv4.2 |
| Latency distribution | 67% requests between 750-1000 µs | 70% requests under 500 µs | NFSv4.2 has tighter and lower latency spread |
| Max completion latency | 4319 µs | 3057 µs | NFSv4.2 max latency about 30% lower |
| CPU Usage (sys%) | 2.85% | 3.37% | Slightly higher system CPU load for NFSv4.2 |
| Disk Utilization | 96.42% | 95.84% | Both very high, similar disk busy |
The comparison between NFSv3 and NFSv4.2 clearly shows that NFSv4.2 delivers better performance in terms of both throughput and latency. The IOPS and bandwidth achieved with NFSv4.2 are about 45% higher, which reflects significant improvements likely due to advancements in the protocol such as enhanced caching, more efficient operations, and improved integration with the network stack. Latency also sees a notable reduction, with the average completion latency dropping from around 598 microseconds to about 412 microseconds, resulting in quicker response times for random input/output workloads.
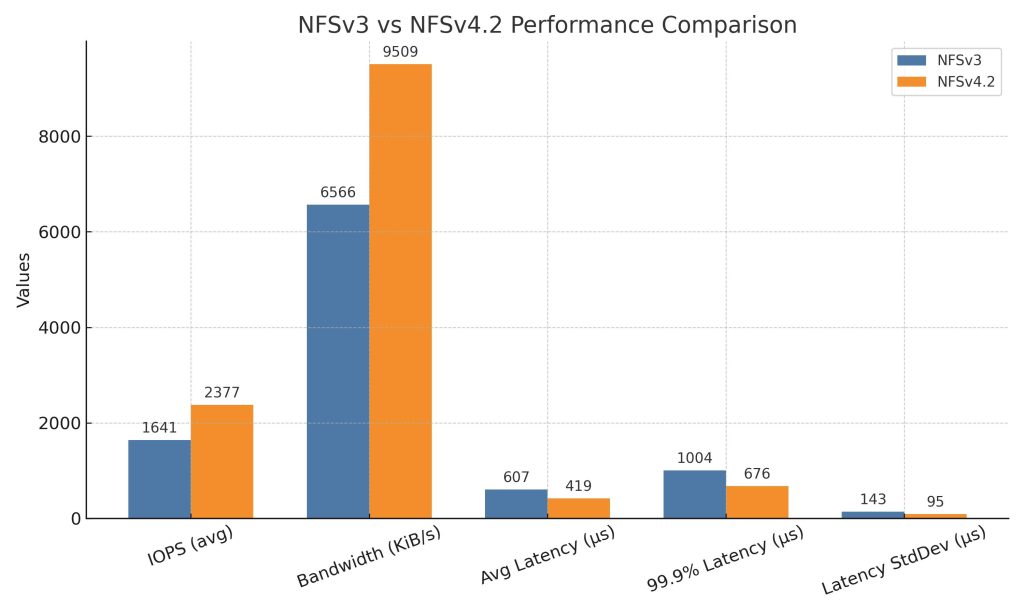
Furthermore, the latency distribution under NFSv4.2 is more consistent and generally lower, with most requests completing in under 500 microseconds, whereas NFSv3 has a wider range with many requests falling between 750 and 1000 microseconds. While CPU usage is a bit higher for NFSv4.2, likely due to the additional features and kernel activity, this trade-off is common when achieving better performance and lower latency. Both setups show very high disk utilization, indicating that the tests are pushing the disk subsystem to its limits in either case.
Conclusion
The results clearly show that NFSv4.2 has a noticeable edge over NFSv3 when it comes to performance. With around 45% higher IOPS and bandwidth, it’s obvious that the protocol improvements, like better caching, more efficient operations, and tighter network stack integration really pay off. Latency is also much better with NFSv4.2, averaging around 412 microseconds compared to 598 microseconds with NFSv3. Even more importantly, the latency is more consistent, with most requests finishing under 500 microseconds, whereas NFSv3 tends to be more all over the place, often falling between 750 and 1000 microseconds. Sure, CPU usage is a bit higher with NFSv4.2, but that’s a fair trade for the performance gains. Both setups max out the disk backend, so the bottleneck isn’t in the protocol but in the storage itself.
That said, there’s still room to push things further when really needed. Switching to NVMe-oF opens up new possibilities, especially when combined with SPDK to cut down latency and boost efficiency even more. I’ll cover how to get the most out of NVMe-oF and SPDK in one of my next posts. But in the end, NFSv4 provides a much easier setup which is also fully integrated into the Proxmox UI without invoking the cli which makes it more user friendly and still provides reliable latencies and bandwidth.
[…] NFSv3 vs NFSv4 Storage on Proxmox – Latency Clash That Reveals More Than You Think. https://gyptazy.com/nfsv3-vs-nfsv4-storage-on-proxmox-the-latency-clash-that-reveals-more-than-you-t… […]
Comments are closed.